
At the park
At the park
There are more important things going on in the world than map controversies, but the historical role of the U.S. government is not to dictate place names, but to create the database in order to facilitate commerce, uniformity, etc. Does the database maintainer have some amount of power over naming? Yes, but if the databases hadn’t existed and been reliable over the last 20 years, tech companies would have just made their own from scratch. If the official government sources become propaganda, you should stop depending on them.
Everyone knows time zones are hard. I know time zones are hard. But that didn’t prepare me for the mess I got myself into dealing with incorrect time zones between my Sony camera and Apple Photos.
Let me start with some conventions, so this doesn’t get any more confusing than
it has to be. I’m going to say naive time for the date and time that
you see on a clock, without any time zone information, like
2024-01-27 12:00:00. I will say absolute time to
mean an actual point in time, independent of time zones. This is usually
written as a naive time plus a UTC offset, such as
2024-01-27 12:00:00-0800 or
2024-01-27 15:00:00-0500. Note that those two absolute times
are in fact the same time. Changing UTC offsets is like a change of units,
nothing more.
I’m going to say time zone for the geographical location where a time
exists, which is usually specified by a major city in the zone, such as Los
Angeles. I will say offset to mean the difference between UTC and a
particular timezone at a particular time, which is usually written as -0800
for eight hours behind UTC.
The distinction between a time zone and an offset is subtle. The key difference is that a time zone doesn’t change throughout the year (unless laws change significantly), but the offset for a given time zone can, and often does due to Daylight Saving Time (DST hereafter). You can’t figure out a time zone from a time plus offset, but you can guess (Phoenix and Los Angeles have the same offset in the summer, but they aren’t the same time zone). You can usually figure out an offset from a naive time plus a time zone, but there are ambiguities, like 1:30 am on a certain Sunday in November.
The time information for a photo is stored in EXIF format in two separate
fields: DateTimeOriginal stores a naive time, and OffsetTimeOriginal stores
the UTC offset. EXIF does not store the time zone, only the offset.
Ideally, programs handle changing the time zone (which is mostly a display preference) separately from correcting the absolute time. (Spoiler! They don’t.)
The problem started with my Sony camera thanks to a bad user interface and, I
suppose, user error on my part. The camera has three separate settings:
“Date/Time,” “Daylight Savings [sic],” and “Area Setting.” I set it up in the
winter with the correct time and location, but set “Daylight Savings” to “On”
because I thought that it was offering to automatically adjust for DST. What it
actually did is set the offset to -0700, even though the correct offset in
the winter is -0800.
This means that all of the pictures I took got not only the wrong time zone, but also the wrong absolute time. I first noticed it when my Sony photos and my iPhone photos were in the wrong order in Apple Photos, despite the time seeming to be set correctly on the camera. But more on that below.
The “correct” way to use the camera settings is to first set the location and Daylight Savings setting, and then set the time. From then on, whenever you adjust the location (because you traveled) or the Daylight Savings setting (every March and November), it automatically adjusts the Date/Time in the correct direction. If you forget to change either of these, at least you will still record the correct absolute time. But if you ever try to fix the time without first correcting the other two settings, you will end up with the wrong absolute time.
Let me first note that if you import RAWs into Apple Photos, it does all sorts of weird things to the time zones:
It’s an absolute madhouse, but I generally don’t put RAWs into Apple Photos.
If you import JPEGs into Apple Photos, it sees the offset. The Info pane
shows only the photo’s naive time, but the photos are sorted according to
absolute time. This is how I first discovered that my camera settings were
wonky. I had a photo taken at 10:00 by my Sony that was sorted before one taken
at 9:30 by my iPhone, because one was stored correctly as 09:30:00-0800, and
the other was stored incorrectly as 10:00:00-0700, which is the same as
09:00:00-0800.
To fix the incorrect time zone in Photos, you can use the “Adjust Date and Time” dialog box, which is in the menu bar or can be triggered by double clicking the time in the Info pane. As far as I know, this is the only place where you can see the time zone information. If you do change the time zone, the dialog “helpfully” adjusts the time in the opposite direction, so that by default (as long as you are operating on only one photo, more on this in a minute) you are changing only the time zone and not the absolute time. But if you counteract this and set the new time to the same as the old time, they you can convince Photos to change only the time zone.
If you manage to set the absolute time correctly on your camera but forget to adjust it for traveling or Daylight Saving Time, the assist from the dialog box is exactly what you need. Just change the time zone and the fixes to the naive time will be exactly what you want to preserve the original absolute time. Here is an example where I changed from -0500 (set nonsensically in my camera as Central Daylight Time even though it is winter) to -0800. The message says, “The original photo will be adjusted by -3 hours” which is a little confusing, but once you understand exactly what is going on, it will make more sense.
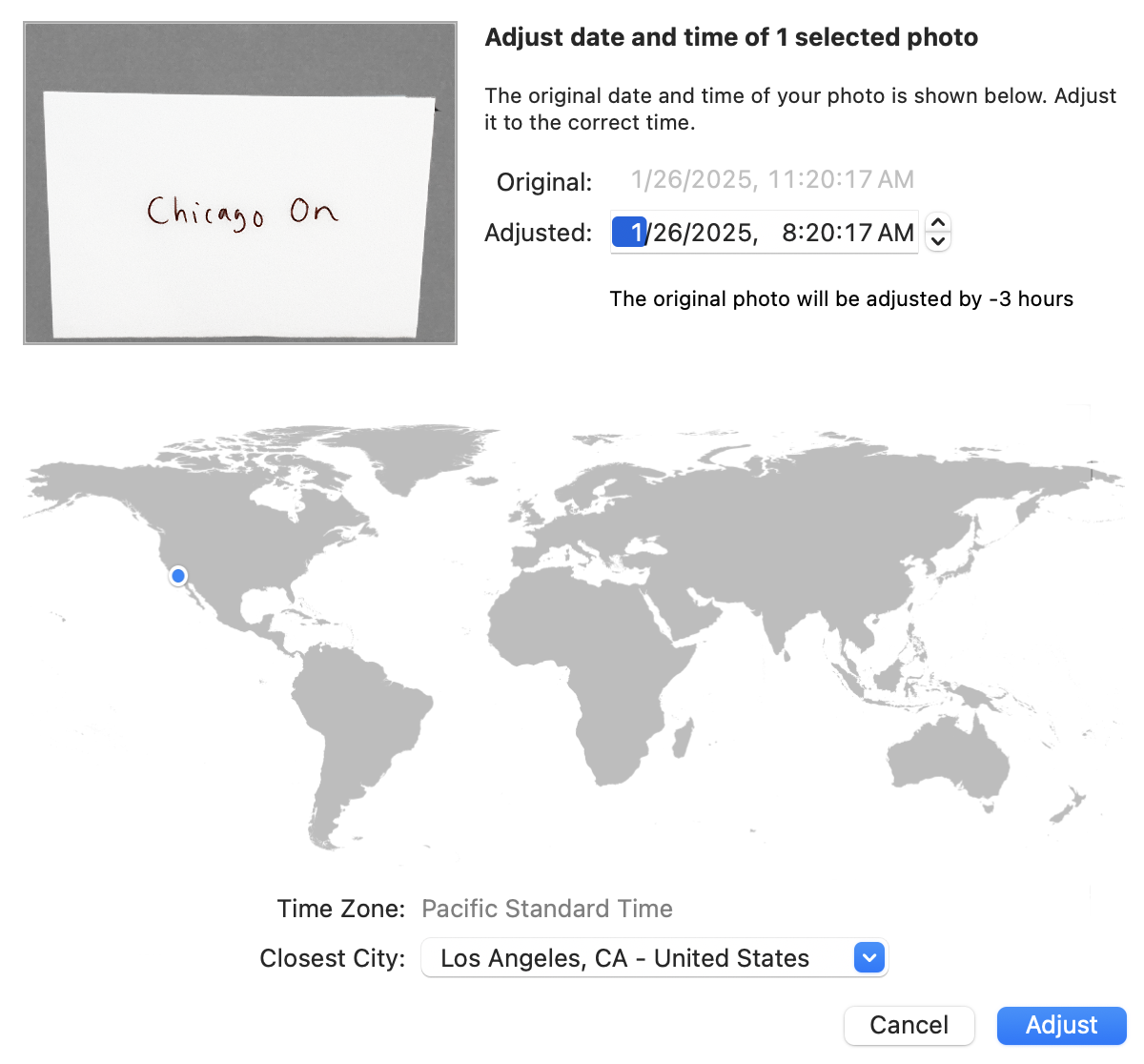
So far, everything is mostly understandable once you figure out what is happening, though the user interface remains confusing and is further complicated by the fact that the time zone itself isn’t visible in the Info pane. But it gets worse.
“Adjust Date and Time” can be and usually is used on multiple photos at once. It would be far too many clicks to make the adjustment for every single photo individually. It shows you the first photo and has you pick the new date, time and time zone, and then it applies “the same” relative adjustment to every photo in the batch.
If you are adjusting absolute times, a batch operation makes sense, and in fact you can just alter all of the naive times and leave the offsets alone and this would be technically correct, although with DST boundaries it could push some times into offsets that are nonsensical for the time zones where they were taken.
If your goal is to correct the time zones while preserving the absolute times, it is also clear what the batch operation should be.
Unfortunately, Photos combines both time adjustments and time zone adjustments into the same operation, and it will only do something sensible if all of the selected photos have the exact same time zone to begin with. It also makes the time-zone-only transformation difficult and error prone.
As far as I can tell, the batch edit is always performed as the following two separate transformations:
In particular, this means that there is no way to correct time zones while preserving absolute times. That is, if you change the time zone for several photos which are not all from the same time zone, you will adjust the absolute times by varying amounts. Here is plausible scenario:
11:07:00-0800 because you forgot to change the time
zone14:09:00-0500Later, you select the two photos in Apple Photos and begin to batch change the
time zone to NYC. The dialog suggests changing the time to 2:07 p.m., which is
correct for the first photo. This is implemented as “change offset to -0500
and add 3 to the naive time.” The first photo gets a new time of
14:07:00‑0500 (good job), and the second changes to
17:09:00‑0500. Oops.
I use Day One a lot, jotting down thoughts or memories, or anything that I might forget. It is often useful to be able to remember what I was doing or thinking around a given time in the past.
I also use Letterboxd to track the movies that I watch. Sometimes it is helpful to remember whether or not I have seen a movie and whether or not I enjoyed it. It also helps manage my watchlist and gives me recommendations from friends.
I thought it would be fun to combine the two, so that I can use Day One to remember when or if I saw a movie. Letterboxd has RSS feeds and Day One has a MacOS command line interface (you can install them from a menu item in the app).
So here is a Python script to parse the RSS feed, download the poster, and create a new Day One entry.
|
|
I created a separate journal in Day One called “Media” for these, so that they can be separate from my normal entries.
The GUID of each entry is written into a state file, so that I don’t download
anything more than once. I used 'r+' so that I can both read and write.
After reading the entire file, the cursor is at the end, which is where the
writes happen. It also requires that the file already exist, which I appreciate
because it means if I give it the wrong filename, it will crash instead of
creating the entire set of entries again.
NamedTemporaryFile creates and opens a temp file where the poster image can be
stored. By setting delete_on_close=False, I can close the file and it stays
around until the end of the context block. If you are reading closely, you may
notice that it creates and then deletes a temp file even if there is no image.
I’m okay with that.
ElementTree does a weird thing where the object returned by item.find()
evaluates to False even if it exists. This is why there are a bunch of
if o is not None instead of the simpler if o.
Lastly, the RSS feed only has about 25 entries. If you want older data, you’ll have to get that some other way. Letterboxd doesn’t have a publicly available API, but they will give you a CSV file, and each row has a link to the movie page. With a little work (and don’t forget to set the user agent), you can scrape a bunch more posters.
As a bonus, the image view in Day One gives me a nice looking table of my watch history. Here is what I was doing about nine months ago.

It’s sad to see so many people going along with or cheering on Trump’s inhumane and cruel policies. I like to imagine that someday they’ll realize what he is and feel shame for their support, but who am I kidding? Even those who were on the side of racism during the civil rights movement never felt a bit of remorse.
Also going through my head this morning:
I hope you’re proud how you would grovel in submission
To feed your own ambition
So though I can’t imagine how
I hope you’re happy now
I’m trying a couple of new things on this site.
One is to be a little less guarded about myself. I’m sometimes afraid to overshare and so end up overly reserved. I’ve started with a more comprehensive and personal about me page.
I’ve been posting some photos using the Glass app over the last couple of years, and I’ve now copied them here as well, along with an RSS feed.
Since I last analyzed my electricity usage two years ago, several things have changed:
To extract the data in Python, using the built-in xml.etree module to convert
to a Pandas series, I reused most of the code from last time:
from xml.etree import ElementTree
import datetime
import pandas as pd
ns = {'atom': 'http://www.w3.org/2005/Atom', 'espi': 'http://naesb.org/espi'}
root = ElementTree.parse('/path/to/file.xml').getroot()
prefix = "./atom:entry/atom:content/espi:IntervalBlock[@rel='Delivered']/espi:IntervalReading"
times = [datetime.datetime.fromtimestamp(int(x.text))
for x in root.findall(prefix + "/espi:timePeriod/espi:start", ns)]
values = [float(x.text)
for x in root.findall(prefix + "/espi:value", ns)]
ts = pd.Series(values, index=times).sort_index()
The main difference is the addition of [@rel='Delivered'] to filter to only
power delivered to me and not the other way around. I also added the
sort_index command, because for some reason the dates are not entirely in
order in the XML.
At this point, I wanted to determine when I was charging a car. Charge loads are probably pretty easy to isolate, because they last for a long time and are relatively constant. If I were trying to be robust, I would probably figure out what expected power draw for a given time of year and time of day, and then find out periods where the draw is significantly higher than that. Using something simple like the median of the surrounding 14 days of a given time would probably work, since I charge less than half of the days.
But in my case, the 7.5 kW of power that our electric Mini draws is more than our entire house uses over any 30-minute period. There are five 15-minute periods that reach that level, but these are relatively easy to filter out.
I wrote this code to compute the charge state. I wanted to separate it into cycles of “off”, “start”, “on”, and “stop”. My thinking was that these “start” and “stop” periods are probably times where I was charging the car for some but not all of the 15-minute period. I used a threshold of 1800 Wh, which is 7.2 kW over a 15-minute period.
|
|
Line 2 creates a new series with the same index as our time series. We then
look at the entries one by one and determine when to transition to “start”
(Line 13, if we are not already charging and we see two upcoming entries above
the threshold), when to stay “on” (Line 6, as long as we stay above the
threshold), when to transition to “stop” (Line 8, as soon as we first go below
the threshold). Note that Pandas uses iloc to look up an entry by integer
offset, rather than by time.
With this charge_state series, it is easy to play around with the data. For
example, to count how many charge sessions:
sum(charge_state == 'start')
To look at the entries where usage is high but you aren’t charging. This means
“filter ts to points where it is above the threshold but charge_state is off.”
ts[(ts > THRESHOLD) & (charge_state == 'off')]
Finally, a good visualization is always helpful to understand the data. I don’t usually use much ChatGPT while programming, because at work I am usually dealing with complicated code that I don’t want to mess up. But it is impossible to remember how to do anything in Matplotlib, and I confess that I asked ChatGPT for a lot of help, and it did a pretty good job most of the time.
Here my goal is to draw dots at start and stop time for each charge, and connect them with a line. I really just have three arrays here:
start_time is the full date and time when I started charging. This is used
as the x axis.start_hour is the time of day when I started charging.charge_hours is the number of hours that I charged.Note that since charging often happens overnight, I’m using the end time as
start_hour + charge_hours, which might be greater than 24, but I think that makes a
better visualization than wrapping around to the bottom.
|
|
And here is the final result. The Mini only has a 32 kWh battery, so can always fill in four hours or so. The longer lines from December are for the new car, which has triple the battery size, but also can max out the 50-amp circuit that my charger is on by pulling 9.5 kW. (If you do the math, that is only 40 amps, because code require that a continuous load uses only 80% of the rated amperage.)
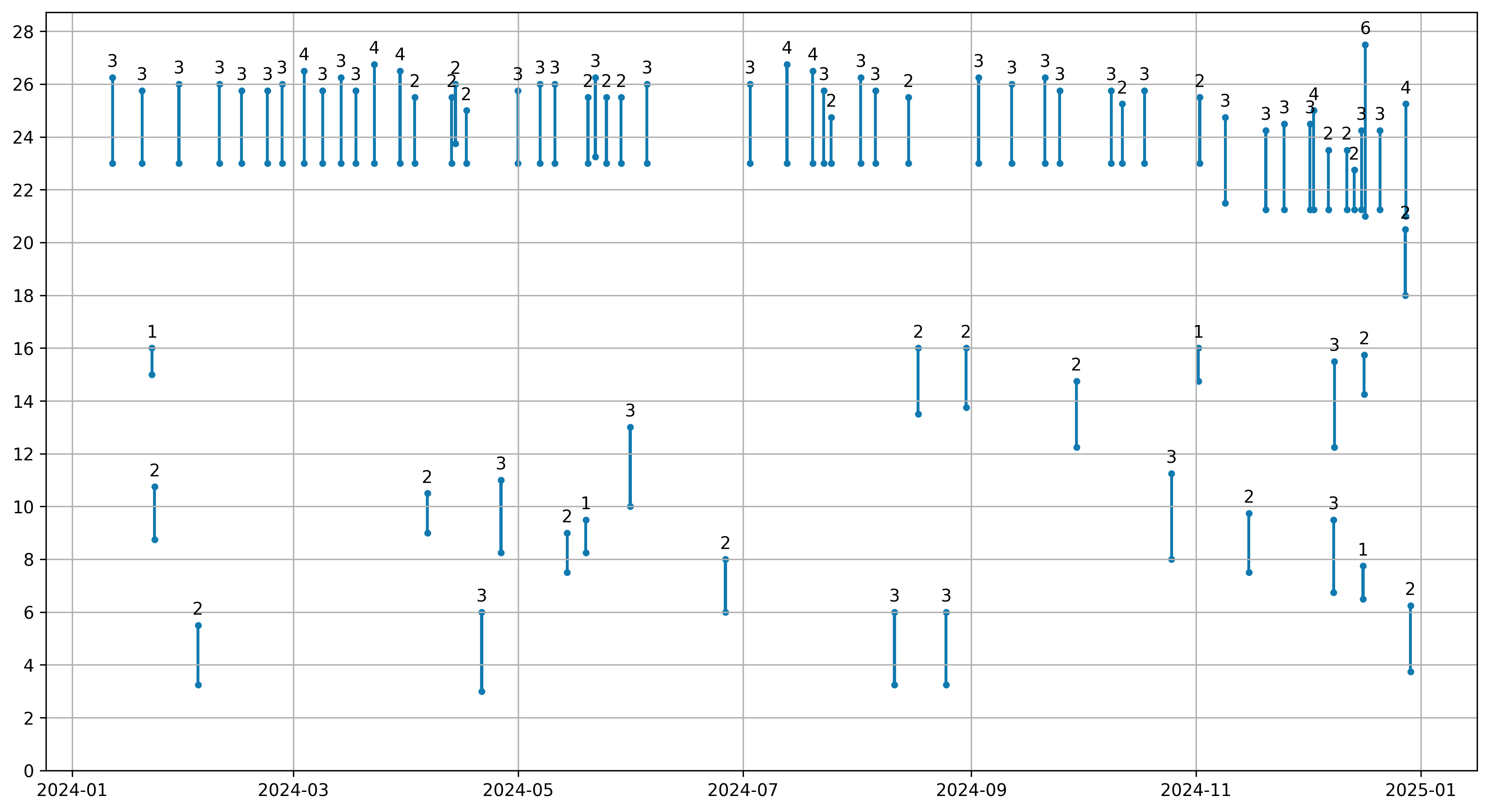
The Mini used to be scheduled to start at 11 p.m., because it draws 30 amps on our 100 amp service, and I was afraid that if I charged it while everyone was still awake it might trip the breaker. In November, I decided to stop babying our house, and scheduled the charge to start at 9:15 instead. Cheap electricity starts at 9:00.
Also, a quirk of the Mini app is that if you plug it in on a Saturday night (the way my schedule is set), it won’t start charging until Sunday morning at 3:00. That is a long story for another time.

The back side of a clock from inside Musée d’Orsay. In the distance, the Louvre.

Welcoming courtyard

Ancient Roman Arena, Arles, France

The Camargues, France

Cloître Saint-Trophime, Arles, France

View of the river from Pont du Gard, France

Pont Neuf and Square du Vert-Galant, Paris
Boats along the Seine