My thermostat just showed me an advertisement. I’m not happy about this.
Here is a great article on OmniFocus, its current state, and useful tips by Gabe Weatherhead. Like Gabe, I recently started using OmniFocus 2 after some years away.
One of the main lessons that I have learned in the last three years in my
job as a programmer is that if you only have to do a job once or twice,
use brute force.
Today, I was setting up a Synology NAS.
The instructions for getting started are extremely sparse, consisting mainly of
“type in the IP address in a web browser and follow the instructions there.”
In the old days, I would have started typing IP addresses until I found one that
worked. Today, I made a new directory called “ips” and ran
for i in $(seq 50);doecho"curl 10.0.1.$i > $i"done| parallel -j 25
Then, since I am (obviously) impatient, I ran wc -l * every few seconds to see
which files were not empty. I found it at 10.0.1.5.
Later I discovered find.synology.com, which is the official
way to find your Synology.
I got an Apple Watch for my birthday. So far, the best part is easy access to my calendar while I’m at work.
I would like to write more regularly, so I’m experimenting with a shorter post format,
what Manton Reece calls a microblog
post. I spent some time today tweaking my Jekyll configuration to enable them on this site.
Workflow is an iOS app that lets you build a simple program by
dragging blocks around, similar to Apple’s Automator app that ships with macOS.
A recent update makes it possible to send a wider variety of
HTTP requests, which allows you to interact with web APIs that aren’t otherwise
supported.
Or, if you have a web server, write your own API.
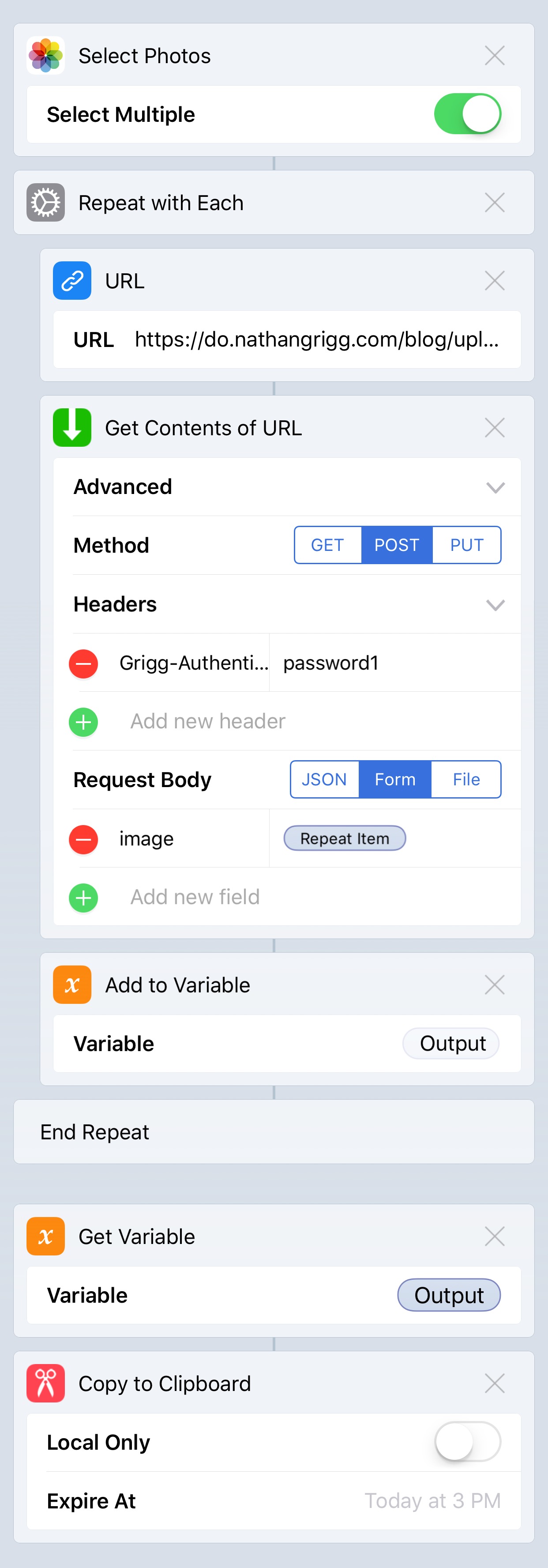
Upload images workflow
Here is a workflow to take images from my phone and upload them to my server.
It makes one request per image.
It sets the custom header Grigg-Authentication to make sure that random people
aren’t uploading images.
It puts a file into the POST request with field name image.
The responses will be HTML image tags, which are collected and then
copied to the clipboard.
Flask
Flask is a Python web framework.
It makes it very easy to map URLs to Python functions.
The first thing I wrote was a private decorator, that would check the
HTTP headers for my authentication key. It doesn’t have to be a decorator, but
that makes it easier to reuse in the future.
If you are not using a secure (HTTPS) connection, somebody could read your
authentication key and pretend to be you.
You can set this up directly with Flask, but since I’m already
running nginx, I used that.
(I will share the details in a future post.)
Next, there is some basic Flask setup.
I changed the response MIME type to plain text
and registered an error handler that will report any exceptions
in the response, rather than logging an error where I won’t see it.
Then, there is the routing code. This function is called
every time someone visits /blog/upload-image,
as specified in the route decorator.
1
2
3
4
5
6
7
8
9
10
11
@app.route('/blog/upload-image',methods=['POST'])@privatedefblog_upload_image():try:fh=flask.request.files['image']exceptKeyError:flask.abort(400,'Expected a file with key "image", not found')_,extension=os.path.splitext(fh.filename)filename=upload_image(fh,extension)return'<img src="{}" class="centered">\n'.format(filename)
Finally, the actual work is done by the upload_image function.
I save the image into a dated directory with a random filename, then
run a bunch of git commands.
classError(Exception):passdefrandom_chars(size):returnbase64.b32encode(uuid.uuid4().bytes).decode('ascii').lower().rstrip('=')[:size]defupload_image(fh,extension):"""Upload image to blog and return filename, relative to site root."""subdir='images/{:%Y}'.format(datetime.datetime.today())try:os.mkdir(os.path.join(PATH,subdir))exceptFileExistsError:passbasename=''.join((random_chars(8),extension))filename=os.path.join(subdir,basename)fh.save(os.path.join(PATH,filename))output=[]defrun(args):output.append(' '.join(args))output.append(subprocess.check_output(args,cwd=PATH,stderr=subprocess.STDOUT))try:run(['git','pull','--ff-only'])run(['git','add',filename])run(['git','commit','-m','Add image'])run(['git','push'])exceptsubprocess.CalledProcessError:raiseError('Git operation failed. Output:\n{}'.format('\n'.join(output)))returnfilename
Chile’s Ministry of Energy announced today that Chile will be observing
daylight saving time again. Chile Standard Time will be changed back to UTC
-4 at 00:00 on 15 May, and DST will be observed from 00:00 on 14 August 2016,
changing time in Chile to UTC -3.
Chile used to observe DST every year until a permanent UTC offset of -3 was
introduced in 2015.
It is unclear whether the time change also applies to Easter Island.
I was looking to make more room on my phone’s home screen, and I realized that
my use of App.net had dwindled more than enough to remove it. I never
post any more, but there are a couple of people I would still like to follow
that don’t cross post to Twitter.
App.net has RSS feeds for every user, but they include both posts and replies.
I only want to see posts. So I brushed off my primitive XSLT skills.
I wrote an XSLT program to delete RSS items that begin with @. While I was at
it, I replaced each title with the user’s name, since the text of the post is
also available in the description tag.
Here is the transformation that would filter my posts, if I had any:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
<?xml version="1.0" encoding="UTF-8"?><xsl:stylesheetversion="1.0"xmlns:xsl="http://www.w3.org/1999/XSL/Transform"><!-- Default identity transformation --><xsl:templatematch="@*|node()"><xsl:copy><xsl:apply-templatesselect="@*|node()"/></xsl:copy></xsl:template><!-- Replace title with my username --><xsl:templatematch="item/title/text()">nathangrigg</xsl:template><!-- Remove completely items which are directed at other users.
The RSS feed has titles of the form @username: text of post. --><xsl:templatematch="item[contains(title, '@nathangrigg: @')]"/></xsl:stylesheet>
Now I can use xsltproc to filter the RSS.
In order to fill in the username automatically, I wrapped the XSLT program in a
shell script that also invokes curl.
#!/bin/bash
set -o errexit
set -o pipefail
set -o nounset
if(($# !=1));then >&2echo"USAGE: $0 username"exit1fiusername=$1xslt(){cat << EOM
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<!-- Default identity transformation -->
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
<!-- Replace title with just the username -->
<xsl:template match="item/title/text()">$username</xsl:template>
<!-- Remove completely items which are directed at other users.
The RSS feed has titles of the form @username: text of post. -->
<xsl:template match="item[contains(title, '@$username: @')]" />
</xsl:stylesheet>
EOM}rss(){ curl --silent --fail https://api.app.net/feed/rss/users/@$username/posts
}xsltproc <(xslt) <(rss)
While adding multithreading support to a Python script,
I found myself thinking again about the difference between multithreading and
multiprocessing in the context of Python.
For the uninitiated, Python multithreading uses threads to do parallel
processing.
This is the most common way to do parallel work in many programming languages.
But CPython has the Global Interpreter Lock (GIL), which means that
no two Python statements (bytecodes, strictly speaking) can execute at the same
time. So this form of parallelization is only
helpful if most of your threads are either not actively doing anything
(for example, waiting for input),
or doing something that happens outside the GIL
(for example launching a subprocess or doing a numpy calculation).
Using threads is very lightweight, for example, the threads share memory space.
Python multiprocessing, on the other hand, uses multiple system level processes,
that is, it starts up multiple instances of the Python interpreter.
This gets around the GIL limitation, but obviously has more overhead.
In addition, communicating between processes is not as easy as reading and
writing shared memory.
To illustrate the difference, I wrote two functions. The first is called idle
and simply sleeps for two seconds. The second is called busy and
computes a large sum. I ran each 15 times using 5 workers, once using threads
and once using processes. Then I used matplotlib to visualize the
results.
Here are the two idle graphs, which look essentially identical.
(Although if you look closely, you can see that the multiprocess version is
slightly slower.)
And here are the two busy graphs. The threads are clearly not helping
anything.
I have a Python script that downloads OFX files
from each of my banks and credit cards.
For a long time, I have been intending to make the HTTP requests multithreaded,
since it is terribly inefficient to wait for one response to arrive before
sending the next request.
Here is the single-threaded code block I was working with.
1
2
3
4
5
6
7
8
9
10
11
defReadOfx(accounts):downloaded=[]foraccountinaccounts:try:account.AddOfx(read_ofx.Download(account))excepturllib.error.HTTPErroraserr:print("Unable to download {}: {}".format(account,err))else:downloaded.append(account)returndownloaded
Using the Python 2.7 standard library, I would probably use either the
threading module or multiprocessing.pool.ThreadPool.
In both cases, you can call a function in a separate thread but you cannot
access the return value. In my code, I would need to alter Download
to take a second parameter and store the output there. If the second parameter
is shared across multiple threads, I have to worry about thread safety.
Doable, but ugly.
In Python 3.2 an higher, the concurrent.futures module
makes this much easier. (It is also backported to Python 2.)
Each time you submit a function to be run on a separate thread, you get a Future
object. When you ask for the result, the main thread blocks until your thread is
complete. But the main benefit is that I don’t have to make any changes to
Download.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Among other imports, we have `from concurrent import futures`.defReadOfx(accounts):withfutures.ThreadPoolExecutor(max_workers=10)asex:ofx_futures=[(account,ex.submit(read_ofx.Download,account))]print("Started {} downloads".format(len(ofx_futures)))downloaded=[]foraccount,futureinofx_futures:try:account.AddOfx(future.result())excepturllib.error.HTTPErroraserr:print("Unable to download {}: {}".format(account,err))else:downloaded.append(account)returndownloaded
In a typical run, my 6 accounts take 3, 4, 5, 6, 8, and 10 seconds to
download. Using a single thread, this is more than 30 seconds. Using multiple
threads, we just have to wait 10 seconds for all responses to arrive.
I have been using IPython for interactive Python shells for several
years.
For most of that time, I have resisted the web-browser-based
notebook interface and mainly used the console version.
Despite my love of all things texty, I
finally gave in, and began using the web version almost exclusively.
So much that I got annoyed at constantly needing to start and stop the IPython
server and having a terminal dedicated to running it.
Always running server using Launchd
My first step was to always keep the IPython server running.
I did this with a KeepAlive launchd job.
Here is the plist:
This job runs ipython notebook with the --port flag, so that the port
stays the same each time.
I used LaunchControl to create and load this launch agent,
but you can also just save it in ~/Library/LaunchAgents and run launchctl load.
If you want, you can be done now. The notebook browser is running at
http://localhost:10223.
Virtual host and proxy using Apache
But I was not done, because I already had too many processes on my machine that
were serving content at some localhost port. This required me to memorize port
numbers, made Safari’s autocorrect not very useful, and felt barbaric.
What I needed was a domain name that resolved to http://localhost:10223.
To do this, I needed a virtual host and a proxy.
Before reading further, you should know that
I am not an Apache expert.
In fact, I have never managed an Apache webserver
except as a hobby. The best I can promise you is that this works for me, on my
OS X computer, for now.
In /etc/hosts, I created a new host called py.
127.0.0.1 py
This resolves py to 127.0.0.1, i.e., localhost.
Now in /etc/apache2/httpd.conf I created a virtual host and a proxy.
This forwards all traffic to py on port 80 to
localhost on port 10223.
Note that the order of the ProxyPass directives is
apparently important.
Also, if you use * instead of the address in the
VirtualHost directive, you might also be forwarding requests originating
outside of your machine, which sounds dangerous.
Then I ran sudo apachectl restart, and everything seemed to work.
Note that Safari interprets py as a Google search, so I have to type py/.
Chrome does the same thing, except for that after I load py/ once,
the trailing slash is optional.
Apparently I wrote my own. It’s nothing complicated, but it is full featured.
It parses the first line to get the starting line number, then replaces any
existing line numbers with the correct ones.
My script changes
9: a
b
c
to
9: a
10: b
11: c
and
1: a
10: b
11: c
to
1: a
2: b
3: c
It can even remove line numbers if the first line starts with “X:”, so it changes
X: a
2: b
3: c
to
a
b
c
I save it as ~/bin/numberlines, so I can use it on the command line
or by selecting lines and typing ':!numberlines in Vim.
#!/usr/bin/python"""
Number lines on a block of text, preserving indentation.
Allow the first line to indicate start number.
If the first lines starts with 'X:' then remove line numbers.
"""importreimportsysLINE_NO=re.compile(r"^\s*(\d*|[Xx]*):( |$)")lines=sys.stdin.readlines()first_line_number=LINE_NO.match(lines[0])# Determine indentation.indent=min((re.match(" *|\t*",line).group(0)forlineinlinesifline.strip()),key=len)iffirst_line_numberandfirst_line_number.group(1)[0]in"Xx":formatter="{indent}{line}"# These are irrelevant.start=1padding=0else:formatter="{indent}{number:>{padding}}: {line}"start=int(first_line_number.group(1))iffirst_line_numberelse1padding=len(str(start+len(lines)))fori,lineinenumerate(lines):line=LINE_NO.sub("",line[len(indent):])ifnotline:line="\n"sys.stdout.write(formatter.format(indent=indent,number=start+i,padding=padding,line=line))
My favorite shell, zsh, allows you to define a function without assigning
it a name. This turns out to be incredibly useful, and for none of the reasons
that anonymous functions are usually used.
Let’s say I want to copy four or five files from one place to another, but in a
more complicated way than the standard cp command allows.
Obviously, you can just run these commands by using your shell’s history and
editing each time. But editing is hard, especially in the middle of a line and
in more than one place per line.
One way to solve this is with a for loop:
$ for d in 201405082014061020140731 20140802;do> cp $d/old.txt $d/new.txt
> done
But this is not very flexible. If one of the commands fails, you
will probably end up with some copies completed and others not. After fixing the
problem, you will have to remove the copies that succeeded from the for loop.
Another way to solve this problem is write a function and then use it.
(Note that in bash you need to use three lines to define the function.)
This solves the problem of a single command failing, since you can fix it up,
rerun the failed command, and continue along. But it also turns a one-step
process into two. If I later find I need to do two more
copies, I have probably opened a new shell, so I have to first redefine
mycp before reusing it.
Each time you run the command, you just have to find the previous command in
your shell history and edit the final word. If you need to use this same command
tomorrow, you can search your shell history, and again you only need to edit the
final word.
This week Dr. Drang wrote about a useful feature in recent versions of
OS X’s Terminal.app,
which allows you to display a man page in its own special window.
This is especially useful when you want to look something up but you are in the
middle of typing a long command.
It’s not polite to respond to a good solution to a common problem
by claiming to have
a better solution, and even less so when the better solution requires you to
change your shell. But this is the internet, so here goes.
When I need to look at a man page while writing a command, I use zsh’s
push-lineediting command.
This clears the prompt and waits for you to type something else.
After executing this new command, it restores your original prompt.
The nice thing about this is that it is useful beyond just looking at manuals.
Often while typing some command,
I realize I need a quick mkdir or cd or even ls before I’m ready to
execute.
You can bind push-line to a key (I use Ctrl-B) by putting bindkey '^B' push-line
in your .zshrc.
Even better, you can use push-line-or-edit to get the same behavior
with one very useful addition. Normally, if you are typing a continuation line
of a multi-line command, you cannot make changes to prior lines.
But push-line-or-edit redraws the lines as a single block of text,
which allows you to edit anything you have typed so far.
When I started using a script to add items to my TaskPaper file,
I was a little worried about the script making changes to my file while it
was open in TaskPaper. So I used TaskPaper’s preference to save
my files every five seconds, and nothing bad happened for a while.
Then I started seeing corrupted files. It seems like OS X autosave is doing
something weird. If I poke at it, I can get parts of the file go missing,
or sometimes a dialog box pops up to complain. But everything works fine as
long as I do an actual “⌘S” save.
To prevent corruption, I added
a few lines to my shell script, which use AppleScript to save my
TaskPaper file before making the changes.
I use pgrep to check if TaskPaper is running, and a
heredoc to send the text of the script to the osascript binary.
if pgrep TaskPaper > /dev/null;then/usr/bin/osascript << EOM
tell application "TaskPaper"
repeat with Doc in documents whose name is "tasks.taskpaper"
save Doc
end repeat
end tell
EOMfi
(It is so much easier to embed AppleScript in a bash script than the other
way around.)